Joint Inference of Groups, Events and Human Roles in Aerial Videos
Tianmin Shu1, Dan Xie1, Brandon Rothrock2, Sinisa Todorovic3 and Song-Chun Zhu1
Center for Vision, Cognition, Learning, and Autonomy, UCLA1
Jet Propulsion Laboratory, Caltech2
School of EECS, Oregon State University3
Introduction
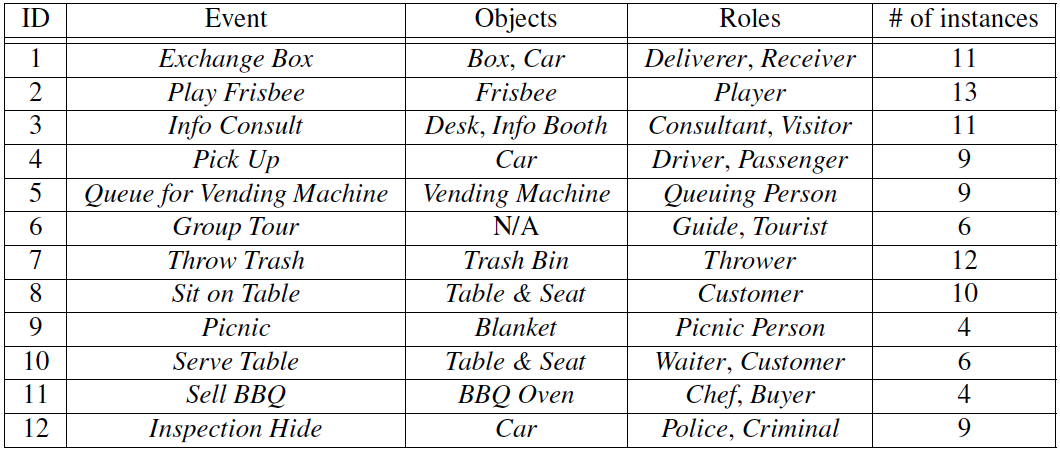
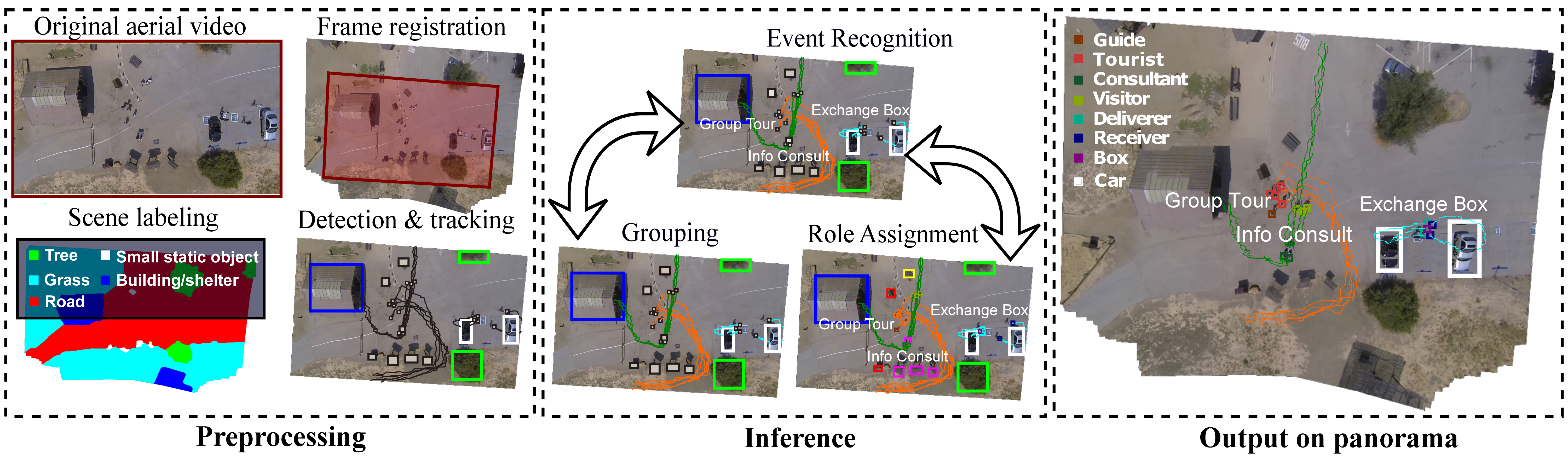
With the advent of drones, aerial video analysis is becoming increasingly important; yet, it has received scant attention in the literature. This project addresses a new problem of parsing low-resolution aerial videos of large spatial areas, in terms of grouping and assigning roles to people and objects engaged in events, and recognizing these events. Due to low resolution and top-down views, person detection and tracking – the standard input to recent approaches to event recognition – are very unreliable. We address these challenges with a novel framework aimed at conducting joint inference of the above tasks, as reasoning about each in isolation typically fails in our setting. Given noisy tracklets of people and detections of large objects and scene surfaces (e.g., building, grass), we use a spatiotemporal AND-OR graph to drive our joint inference, using Markov Chain Monte Carlo and dynamic programming. We introduce a new formalism of deformable templates characterizing latent sub-events. For evaluation, we have collected a new set of aerial videos using a hex-rotor flying over picnic areas rich with group events. Our results demonstrate that we successfully address above inference tasks under challenging conditions.